As Ilya said at NeurIPS, we only have one internet. Once the fossil fuel of existing human-generated data has been consumed, further AI progress requires new sources of information. Broadly speaking, this can happen in two ways: search against a verifier, which trades compute for information, or through direct observation and interaction with the world. So if you want to predict medium-term AI progress, ask “Where is the world rich in feedback?”
There are two major dimensions for scaling AI: pre-training, and inference time scaling1. The most recent cycle of AI progress has been driven by inference time scaling (OpenAI O1). These models are trained with reinforcement learning (RL), which requires a reward signal. Reward is much easier to specify in some domains than others, which is why O1 shows huge performance gains in math and code (domains with verifiable right answers), but little to no improvement in more subjective areas such as writing.
Scaling pre-training with synthetic data is almost the same problem. For generated data to be a net win, you need some quality signal to filter it. So essentially all AI progress now turns on availability of scalable quality/reward signals2.
A skewed pattern of AI progress is therefore likely to persist in the medium term. The graph below shows some areas which have faster and cheaper sources of reward. Those seems like a good bet for where AI will move fastest3.
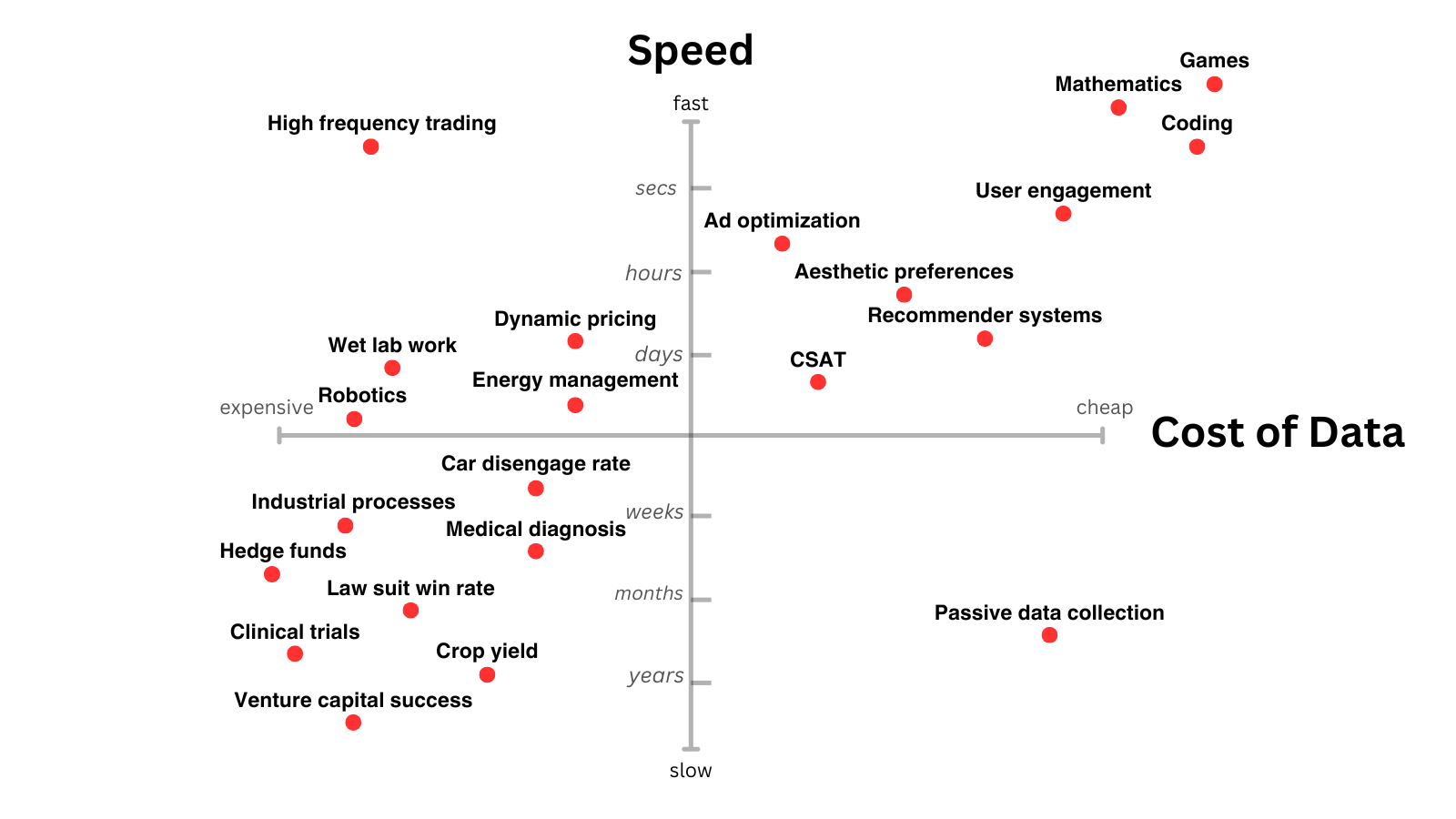
I’ll dig into a few of these areas, and then speculate about how some problems with less precise reward might be addressed.
Games
Games are the ideal environment for RL, and hence where we saw the earliest AI successes, starting with TD-Gammon in 1992. The modern era was kicked off by DeepMind’s deep Q-learning results on Atari in 2013, though it took until 2020 to exceed human-level play on all 57 Atari games. Along the way there were famous results on Go, Starcraft, Poker and Diplomacy among others.
I include this history as a reminder that even though games are the top right of the plot, with cheap and fast rewards, that doesn’t mean they’re a solved problem. Plenty of games remain hard – Nethack for example4. Nevertheless, they are in the sweet spot for deep RL, and AI is gradually exceeding human performance on games broadly.
A particularly powerful tool for RL in games is self-play. AlphaZero famously attained superhuman performance at Go and chess, with zero human training data. It’s hard to overstate how impressive this is. It took the model only hours to rediscover, and improve upon, centuries of human domain knowledge. Ever since these results came out, people have mused about whether there is an equivalent of self-play in LLMs or other domains.
There are a number of ingredients which make self-play work particularly well for games like Go and Chess:
- You have a perfect simulator
- i.e. the game itself. There’s no sim-to-real gap that you’re trying to bridge
- The simulator is cheap to run
- Matches are mostly won or lost, rather than drawn
- You quickly get signal about which agent is better
- Matches are played between agents of similar ability level
- This induces a kind of curriculum learning: most games are at the frontier of the agent’s ability, rather than wasting computation on scenarios that are too far below or above it.
- Matches are relatively short
- On average about 40 moves for Chess, 200 for Go
- The number of possible actions available to an agent at a given time is fairly small
- About 35 for Chess, 250 for Go
- There are effective methods to avoid rock-paper-scissors training dynamics, which can cause agents to go around in circles in policy space
These factors add up to a very favourable environment for reinforcement learning. In general, any two-player zero-sum game is solvable by reinforcement learning via self-play, given sufficient resources.
However, as you move beyond that regime, things become harder. DeepMind’s AlphaStar system for Starcraft has self-play as an ingredient, but human training data was needed to bootstrap it. Meta’s Cicero Diplomacy system also involved self-play, but because success in Diplomacy involves cooperating with human players, the self-play component needs to be carefully constrained to make the results human-compatible5.
All of this is a long way of saying that you shouldn’t extrapolate the dramatic success of AlphaZero too far. There isn’t necessarily an equivalent for other problems.
Mathematics and programming
Apart from games, where else can we find scalable sources of reward? Ideally you want a useful reward signal that’s fully decoupled from human interaction.
Mathematics is one domain that fits the bill. If you task a model with generating proofs, many will be wrong, but a formal verifier such as Lean can tell you which ones are valid. Thus the model has some training signal to work with. The only necessary ingredient is compute, and there is no obvious upper limit to how far you can go6. This gives you a perfect setup for training reasoning models and/or generating synthetic data. OpenAI, DeepMind and Meta all have efforts, and some version of this was clearly a key part of o1. Even IMO-level problems are now close to saturation, and the new focus benchmark is FrontierMath, a problem set so hard that a typical research mathematician would need to phone a friend. Nevertheless, many people expect it to be largely solved within a few years.
Programming is another tractable domain. A compiler provides an external source of feedback, so the model can be rewarded when outputs are syntactically valid. A valid program in itself isn’t very interesting, but additional signals such as test suites and benchmarks can also be used as sources of reward. Self-play is even possible when there is a benchmark to optimize7, and DeepMind has some results on it. Coding is really in a sweet spot, because it’s both economically valuable and amenable to potentially unbounded improvement with minimal human feedback.
It’s worth noting that math and coding are harder learning tasks than self-play games. In particular, you are working with feedback from a yes/no oracle8, rather than the ranking function induced by self-play. If you submit something to the oracle and get a no, nothing tells you how to change your input to get a yes. You might have to burn a lot of computation searching for sparse rewards. This is quite different to self-play, when any outcome other than a draw gives you information about which agent is better. Making math and code tractable needed some additional ideas: process supervision seems to have been a key technique for OpenAI. (Update a few weeks later: DeepSeek demonstrated that this was not correct. RL on outcome rewards is all you need, it’s actually remarkably simple.)
LLM-as-judge
What about unverifiable domains? O1 did not improve at all at general writing tasks, presumably because it was not trained on it. Unlike with math and code, there is no oracle available to tell you which of two essays is the “right answer”.
{kind=link}
This isn’t an impossible problem, but it is a tricker one. One potential avenue comes from the fact that judging tends to be easier than generating. It’s much easier to recognize a good book than it is to write one. There is evidence that LLMs are the same as humans in this regard, and this extends to an LLM judging the output of a model somewhat stronger than itself9. This suggests the possibility of searching for particularly high quality outputs, either via lucky samples or some more expensive inference-time optimization process, and using those outputs to train RL models, or to iteratively improve the base training data. For example, this Tencent paper goes in that direction. You can’t do this forever, but potentially it could go reasonably far without diverging from human quality judgements.
More speculatively, LLM tournaments or agent simulations with competitive dynamics might also provide fertile ground for RL and/or as a source of novel high quality text. Smallville is a nice demo, but as a source of text training data it’s not particularly compelling. However, if the simulated agents take part in any kind of competitive activity, such as debating, elections, dating, earning money, etc, the resulting ranking gives a reward signal to drive learning. You could potentially optimize for an LLM’s ability to persuade other LLMs, for example, and the Cicero Diplomacy system can be seen as a first step along this path. One of the challenges is to ensure that the outputs remain ‘human-compatible’10, but Cicero already showed that this isn’t an intractable problem.
The messy rest
There is only so far you can go inside a sealed box. Beyond a few special cases, you must source reward from the real world.
Collecting a real-world reward signal is easier in some domains than others. The most fertile territory (top right of the graph above) is the human feedback implicit in the exhaust of our digital lives: engagement rates, ad click-throughs, purchase data, etc. These have all been subject to AI optimization for years, and are the basis of huge businesses like TikTok, Meta and Google. I do not think we are done here11, there is still lots of juice to be squeezed with more modern AI methods.
Moving into the real-world proper (bottom left of the graph), data gets more expensive and feedback times get longer. I think many new companies will be built by controlling the data for each of these problems, finding clever ways to collect it cheaply and at scale.
One strategy is to crowd-source it. OpenAI’s recent release of reinforcement fine-tuning is pretty cool, because it unlocks some of these harder applications for users who already have that data. But it also lets OpenAI crowd-source data to improve their models, which could be a major win for them12.
Another strategy is to find a business model that gives you proprietary data. Tesla currently has this for autonomous driving. Intuitive Surgical probably has it for surgery. A start-up called Harrison.AI I think has it for radiology. Intercom has it for customer service. Who will it be for chemistry, law, fish farming, pin manufacturing, etc, etc?
Or at some point do we get a general enough system, with enough transfer learning capacity, that all of this becomes less necessary? Maybe. But so far it seems like we aren’t getting a huge amount of transfer, so we may have to brute force our way to AGI.
What happens next?
Once data must be generated rather than just collected, significant compute budgets will be required for data generation, pushing overall training compute up. Quantifying that is hard until the details become clearer.
In the long run, can you break the tyranny of reality? A little. Simulators reduce your need to gather data from the real world, making things a lot more sample efficient. For example, if we had a very good biology simulation, I doubt it would replace clinical trials, but it might at least greatly reduce their failure rate. Simulators won’t necessarily be classical, they can be learned from data, so you could think of this as just finding more sample-efficient learning methods. The DeepMind neural world model is an early step in this direction.
Speculatively, another question that might become important is “Where can you do online data augmentation well?” That seems to be the key to test time training, which is a potentially complementary way to do inference time scaling. However, it’s still early days for that work, and it’s unclear how important it will be.
Finally, I think all of this could cause model performance from different providers to move apart in interesting ways. Current models are all trained on more or less the same data, and they converge to more or less the same point. If RL training signals and synthetic data pipelines remain proprietary, models may begin to be trained on significantly different data, and this could be a more enduring source of edge for model makers.
Footnotes
- Other post-training techniques have also improved things a lot recently, but you can think of that as basically a layer of polish. I don’t think they have the long-term headroom of pre-training or inference time scaling. ↩︎
- This assumes we don’t get an algorithmic breakthrough on sample efficiency. Humans are trained on a lot less data than LLMs, so sooner or later we probably will figure something out on the algorithmic side. ↩︎
- Though this isn’t the only dimension – the required error rate is probably also a strong predictor. ↩︎
- Agentic LLMs score close to zero at time of writing ↩︎
- From the paper: “Planning relies on a value and policy function trained through self-play RL that penalized the agent for deviating too far from human behavior, to maintain a human-compatible policy.“ ↩︎
- In principle you could have a system which starts from axioms, computes for a long time with no reference to the outside world, and reinvents all of mathematics. ↩︎
- The ultimate version of this involves the model inventing its own problems to solve, thus creating the benchmarks as well as the programs. ↩︎
- i.e the compiler or proof verifier. ↩︎
- For example, Llama 3 uses this general idea as part of their data filtering pipeline: “We found that previous generations of Llama are surprisingly good at identifying high-quality data, hence we used Llama 2 to generate the training data for the text-quality classifiers that are powering Llama 3.” Another example comes from the Reka tech report, which notes that using their LLM as an evaluator to rank the performance of other LLMs aligns almost perfectly with ELO scores from human raters. DeepMind uses LLM-as-judge here. ↩︎
- From the paper: “prior work found that self-play produced uninterpretable language despite achieving high task success for the agents. Even in dialogue-free versions of Diplomacy, we found that a self-play algorithm that achieved superhuman performance in 2p0s versions of the game performed poorly in games with multiple human players owing to learning a policy inconsistent with the norms and expectations of potential human allies” ↩︎
- My Instagram ads for example seem pretty bad, relative to what an AGI that sat down with my data could surely come up with. ↩︎
- Assuming their TOS gives them those rights. ↩︎
I’m not seeing the graph you refer to