Observations on America, and a few on Ireland
I spent some time in the US recently – three months in DC and three months in Chicago. A few observations on daily life, coming from Europe:
MoreListening for the pitter-patter of tiny metal feet.
I spent some time in the US recently – three months in DC and three months in Chicago. A few observations on daily life, coming from Europe:
MoreWhen AI agents start buying things, how do you sell to them?
MoreAI capabilities are continuing to ascend. Coding models crossed a clear threshold at the end of 2025, some programmers no longer write code manually at all. The same transition will play out for many other skills in the next few years. There is wide disagreement about how this will propagate through the economy. Some imagine an instant discontinuity, others expect no meaningful human substitution at all.
To think through how the transition might go, it helps to get very concrete. For most of the last ten years I ran a startup with around 100 employees. What would it take for every role in that company to be replaced by AI?
MoreI’ve been thinking for a while that there’s a piece missing from LLMs. There are hints that this hole might soon be filled, and it could drive the next leg up in AI capabilities.
Many people have observed that LLMs, for all their abilities, seem to lack “spark”. The new reasoning models are remarkably good at a certain kind of knowledge-based problem solving, based on chaining together obscure facts, but they don’t seem to show the novel creative insights that characterize top human solutions. It’s somewhat reminiscent of the Deep Blue era in computer chess: the models approach problems in a grind-it-out kind of way. Humans sometimes do this too, but also have some other mode which the models seem to lack.
Will this just fall out of further scaling? Or do we need some new ideas? While I am very bullish on scaling, I also think ideas are going to matter.
MoreScience fiction stories are a lot more important than Serious People will admit. Most of us are at some level aiming towards or away from things we read as teenagers. Here are a few stories that live in my head as we’re watching the birth of AI:
MoreAs Ilya said at NeurIPS, we only have one internet. Once the fossil fuel of existing human-generated data has been consumed, further AI progress requires new sources of information. Broadly speaking, this can happen in two ways: search against a verifier, which trades compute for information, or through direct observation and interaction with the world. So if you want to predict medium-term AI progress, ask “Where is the world rich in feedback?”
There are two major dimensions for scaling AI: pre-training, and inference time scaling1. The most recent cycle of AI progress has been driven by inference time scaling (OpenAI O1). These models are trained with reinforcement learning (RL), which requires a reward signal. Reward is much easier to specify in some domains than others, which is why O1 shows huge performance gains in math and code (domains with verifiable right answers), but little to no improvement in more subjective areas such as writing.
Scaling pre-training with synthetic data is almost the same problem. For generated data to be a net win, you need some quality signal to filter it. So essentially all AI progress now turns on availability of scalable quality/reward signals2.
A skewed pattern of AI progress is therefore likely to persist in the medium term. The graph below shows some areas which have faster and cheaper sources of reward. Those seems like a good bet for where AI will move fastest3.
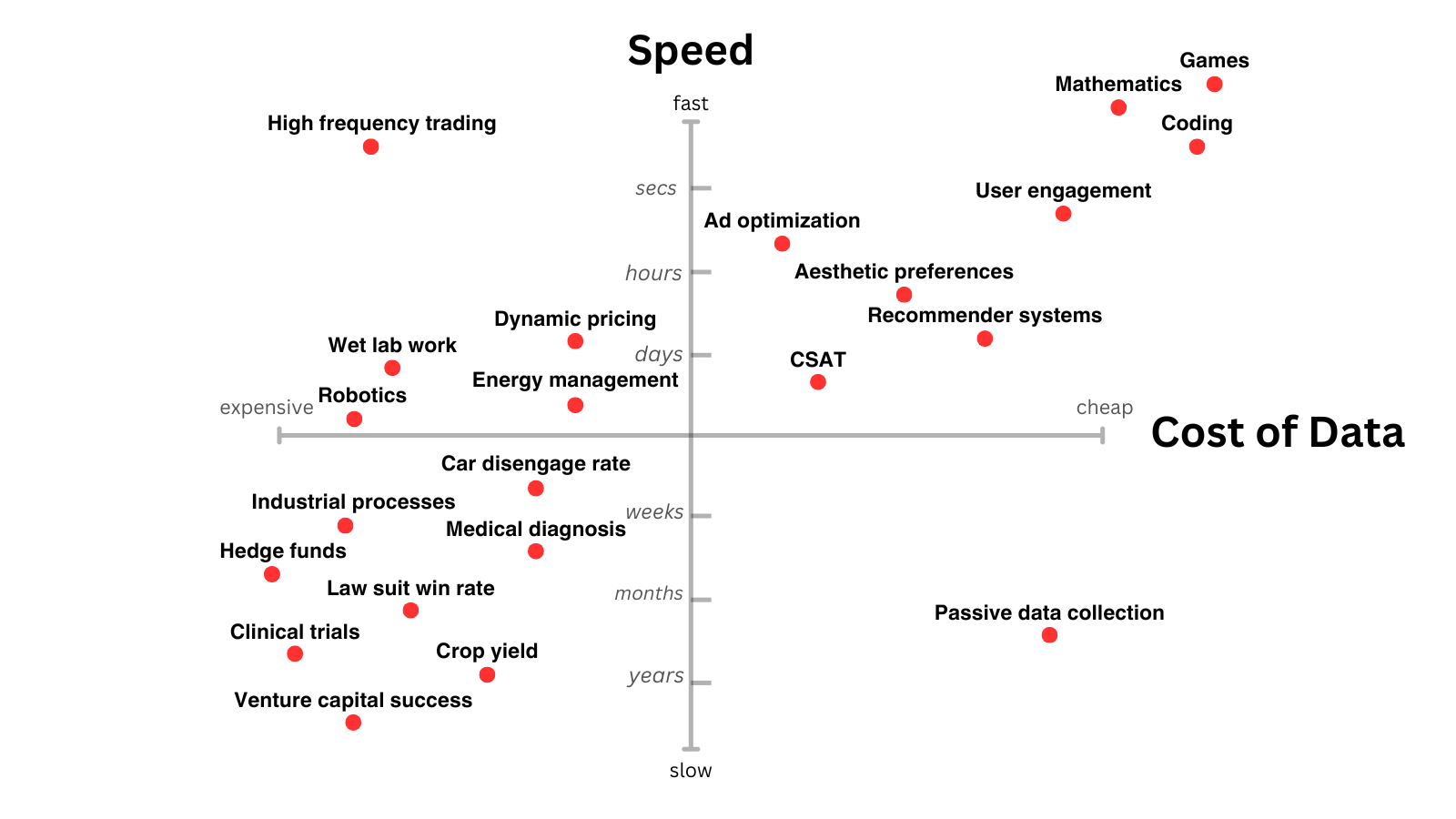
I’ll dig into a few of these areas, and then speculate about how some problems with less precise reward might be addressed.
MoreThe previous post looked at how you might invest for a scenario where AI can do most white-collar work (AGI, roughly speaking), without being broadly superhuman (ASI). However, a short1 transition from AGI to ASI seems plausible, even likely under certain conditions. My focus on the simpler AGI scenario is partly a case of looking for the keys under the streetlight. So in this post I’d like to think through how to invest for a full ASI scenario.
MoreAt this point it seems basically certain that AI will be a major economic transition. The only real question is how far it goes and how fast. In a previous essay I talked through four scenarios for what the coming few years might look like. In this essay I want to think through how to invest against those scenarios.
MoreRecent large language models such as Llama 3 and GPT-4 are trained on gigantic amounts of text. Next generation models need 10x more. Will that be possible? To try to answer that, here’s an estimate of all the text that exists in the world.
MoreThere’s a nice blog post from last year called Go smol or go home. If you’re training a large language model (LLM), you need to choose a balance between training compute, model size, and training tokens. The Chinchilla scaling laws tell you how these trade off against each other, and the post was a nice guide to the implications.
A new paper shows that the original Chinchilla scaling laws (from Hoffmann et al.) have a mistake in the key parameters. So below I’ve recalculated some scaling curves based on the corrected formulas.
More