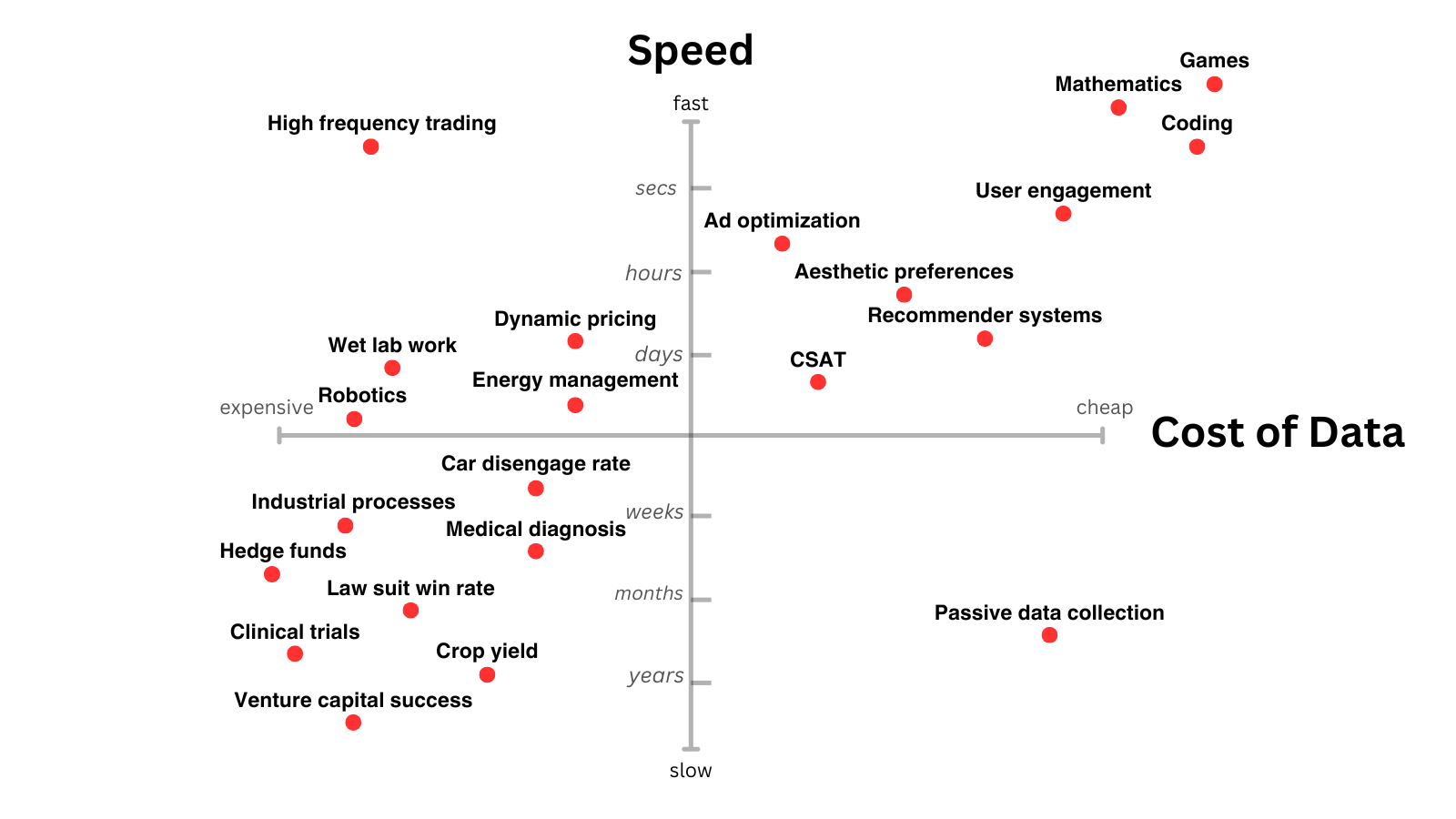
System 3 thinking
I’ve been thinking for a while that there’s a piece missing from LLMs. There are hints that this hole might soon be filled, and it could drive the next leg up in AI capabilities.
Many people have observed that LLMs, for all their abilities, seem to lack “spark”. The new reasoning models are remarkably good at a certain kind of knowledge-based problem solving, based on chaining together obscure facts, but they don’t seem to show the novel creative insights that characterize top human solutions. It’s somewhat reminiscent of the Deep Blue era in computer chess: the models approach problems in a grind-it-out kind of way. Humans sometimes do this too, but also have some other mode which the models seem to lack.
Will this just fall out of further scaling? Or do we need some new ideas? While I am very bullish on scaling, I also think ideas are going to matter.
More